在通常实现的网络上,有Web服务器持有信息和流程请求(请参阅网络服务器的工作方式有关详细信息)。Web浏览器允许单个用户连接到服务器并查看信息。流量众多的大网站可能必须购买并支持数百台机器,以支持用户的所有请求。
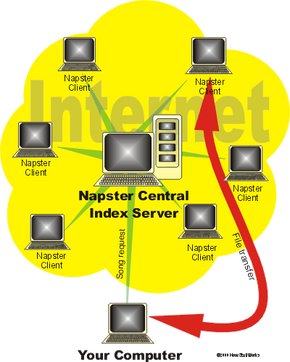
Napster开创了点对点文件共享。凭借旧版本的Napster(Napster于2003年重新启动为合法的,有付费的网站),单个人存储了他们想要共享的文件(通常mp3音乐文件)硬盘并直接与他人分享。用户运行了一块Napster软件,使得共享成为可能。每个用户机器成为迷你服务器。
如果您登录了旧的Napster下载歌曲,那就是发生的事情:
- 您在计算机上启动了Napster软件。您的计算机变成了能够为其他Napster用户提供文件的小型服务器。
- 您的机器连接到Napster的中央服务器。它告诉中央服务器您的机器上有哪些文件。因此,Napster Central服务器在当时连接到Napster连接的每个硬盘上可用的每一首共享歌曲的完整列表。
- 您输入了一首歌的查询。假设您正在寻找警察的歌曲“ Roxanne”。Napster的中央服务器列出了存储该歌曲的所有机器。
- 您从列表中选择了歌曲的版本。
- 您的计算机连接到具有该歌曲的用户机器,并直接从该机器下载了这首歌。
Napster的创建者有几个原因的原因:
- Napster最终越来越多地有数十亿首歌曲。中央服务器无法拥有足够的磁盘空间保存所有歌曲或足够带宽处理所有请求。
- Napster试图利用版权法中的漏洞这使朋友可以与朋友分享音乐。Napster背后的法律概念是:“所有这些人都与朋友在硬盘上分享歌曲。”法院不同意这种逻辑,但它给了足够的时间来证明这一概念并成长为巨大的规模。
这种方法非常出色,并极好地利用了互联网的体系结构。通过将负载扩散以在数百万台机器上下载文件,NAPSTER完成了其他任何方法。
这歌曲标题的中央数据库是Napster的阿喀琉斯脚跟。当法院命令Napster停止音乐时,缺乏中央数据库杀死了整个原始Napster网络。
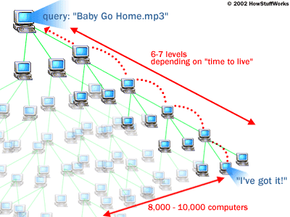
随着最初的纳普斯特(Napster)消失,您当时拥有的是世界各地的1亿人,他们渴望分享越来越多的文件。另一个系统来填补空白只是时间问题。